小规模数据排序(选择、冒泡、插入排序)——算法系列教程(c++版)
梦想不会自己发光,真正闪耀的是那个为梦狂奔的你。献给知行的孩子们!(Eric.He著)
本文详细讲解三大基础交换类排序算法:选择排序、冒泡排序、插入排序,三者均为「原地排序」(空间复杂度极低,仅需常数级额外空间),核心思想简单、代码容易实现,是入门排序算法的必修课。三者的平均时间复杂度均为 O(n2),适合小规模数据排序
教程目录导航
什么是排序算法?
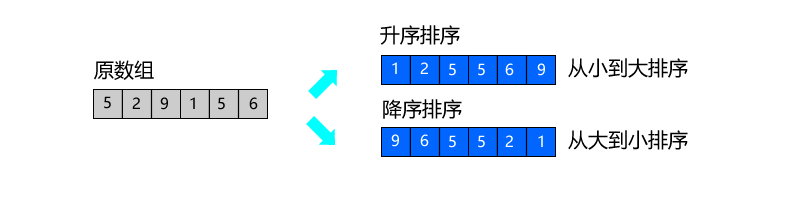
排序算法的核心作用:把一个「无序的数组 / 列表」,按照指定的规则(默认从小到大 / 升序),变成「有序的数组 / 列表」。
比如把 [5,2,9,1,5,6] 变成 [1,2,5,5,6,9],这个处理的过程,就是排序算法要做的事。
一、核心概念
1.1 升序(从小到大排序)
把数组元素从【最小】排到【最大】
比如:[5,2,9,1,5,6] → 升序排序后 → [1,2,5,5,6,9]
1.2 降序(从大到小排序)
把数组元素从【最大】排到【最小】
比如:[5,2,9,1,5,6] → 降序排序后 → [9,6,5,5,2,1]
1.3 时间复杂度
1.3.1 定义
衡量一个算法在执行过程中,「运行快慢」的核心指标,它描述的是:当处理的数据量越多时,算法的执行时间,会以什么样的「速度」增长。
1.3.2 测量
算法执行了多少次循环 / 操作。我们要学的冒泡、选择、插入排序,核心逻辑都是嵌套循环,而时间复杂度的本质,就是看「算法中执行次数最多的循环,会执行多少次」,排序算法的时间复杂度,几乎都由「循环次数」决定!
1.3.3 写法
O(n)、O(n2),这个写法叫做大 O表示法,是时间复杂度的标准写法。
1.3.4 核心规则
- 规则 1:O( ) 里的内容,只保留「最影响增长速度的核心项」
- 比如算法执行次数是 n2 + 2n + 10,我们只保留 n2,时间复杂度就是 O(n2)。
- 原因:当数据量n很大时(比如 n=10000),2n和10的影响微乎其微,只有n2决定了耗时的增长速度。
- 规则 2:忽略「常数项」和「系数」
- 比如执行次数是 2n 或 3n2,时间复杂度依然是 O(n) 和 O(n2)。
- 原因:常数(2、3)只是「固定倍数」,不会改变「增长速度」,比如 3n2 只是比 n2 快 3 倍,但「n 越大,耗时越爆炸」的趋势是一样的。
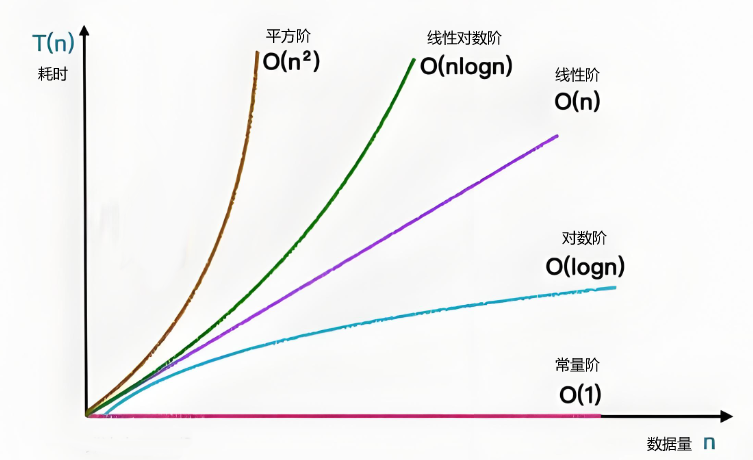
1.3.5 常见复杂度:O(1) < O(logn) < O(n) < O(nlogn) < O(n2)
- O(1)执行次数固定,和数据量 n 无关 → 比如数组取值arr[0]、两数交换,无论 n 多大,只执行 1 次。
- O(logn)我们算法里说的 logn,默认都是 以 2 为底的对数 → log_2n,意思是:一个数 n,每次除以 2,能除几次变成 1,这个次数就是 logn。
- n=8 → 8÷2=4 →4÷2=2 →2÷2=1 → 共除了 3 次 → log_2 8 = 3
- n=16 → 除以 2,需要4 次 → log_2 16 = 4
- n=1000 → 除以 2,需要约 10 次 → log_2 1000 ≈ 10
- n=100 万 → 除以 2,需要约 20 次 → log_2 1000000 ≈ 20
- 算法中只要出现 「每次循环,数据规模就减半」 的逻辑,它的时间复杂度就是 O(logn)。
- 比如:二分查找、二叉树遍历、快速排序 / 归并排序的分治过程,都是这个逻辑。
- O(n):执行次数 和 数据量 n「成正比」→ n 越大,执行次数跟着 n 等倍增长,增长速度很慢,效率很高。
- O(nlogn): O(n) × O(logn)
- 所有 O(nlogn) 的高级排序(快速排序、归并排序、堆排序),核心思想都是 「分治思想」 → 把一个大问题,拆成多个小问题解决,最终合并答案。
- 它们的排序逻辑,都可以拆成 2 个固定步骤,刚好对应两个复杂度相乘:
- 第一步O(logn):把长度为 n 的数组,不断对半拆分,直到拆成一个个只有 1 个元素的小数组;拆分的次数就是 logn 次(比如 n=8,拆 3 次)。
- 第二步O(n):把拆分后的小数组,依次合并并排序,每一轮合并的总比较次数是 n 次。
- O(n2):执行次数 和 数据量 n「成平方关系」→ n 越大,执行次数爆炸式增长,比如 n=100 时执行 10000 次,n=1000 时执行 100 万次,效率较低。
1.3.6 O(n2) 和 O(nlogn) 的效率差距
- 当 n = 1000 时:
- O(n2):执行约 1000×1000 = 100 万次
- O(nlogn):执行约 1000×10 = 1 万次 → ✔️ 快 100 倍
- 当 n = 10000 时:
- O(n2):执行约 1 亿次
- O(nlogn):执行约 10000×14 = 14 万次 → ✔️ 快 700 多倍
- 当 n = 10 万 时:
- O(n2):执行约 100 亿次(直接卡死)
- O(nlogn):执行约 10 万 ×17 = 170 万次 → ✔️ 快 几千倍
1.4 空间复杂度
1.3.1 定义
衡量一个算法在执行过程中,需要占用多少「内存空间」的核心指标。它描述的是:当处理的数据量(n)越多时,算法所需要的内存空间,会以什么样的速度增长。
1.3.2 测量
算法额外申请了多少存储空间,不是「存储原始数据的空间」。比如排序一个数组arr,这个数组本身占用的内存是必须的,不算算法的空间开销,我们只看算法在执行时新申请的变量 / 数组 / 容器占用的空间。
1.3.3 写法
O(n)、O(n2),这个写法叫做大 O表示法,是空间复杂度的标准写法(和时间复杂度写法一样)。
1.3.4 核心规则
- 规则 1:O( ) 里的内容,只保留「最影响空间增长的核心项」
- 比如算法的额外空间开销是n + 10,我们只保留n,空间复杂度就是 O(n)。
- 原因:当数据量n很大时(比如 n=10000),常数10的空间占比微乎其微,只有n决定了空间的增长速度。
- 规则 2:忽略「常数项」和「系数」
- 比如额外空间是 2n 或 3 或 5logn,空间复杂度依然是O(n)、O(1)、O(logn)。
- 原因:常数只是「固定倍数」,不会改变空间的增长趋势。比如 2n 只是比 n 多占一倍空间,但增长速度是一样的。
- 规则 3:只看「运行时申请的最大空间」
- 算法执行过程中,空间可能会「申请后释放」,空间复杂度只看整个执行过程中,占用的内存空间的峰值(最大值),不是累加值。
1.3.5 常见复杂度:O(1) < O(logn) < O(n) < O(nlogn) < O(n2)
- O(1):算法在执行过程中,额外申请的空间是「固定不变」的,不会随着数据量n的增大而增大,无论 n 是 10 还是 100 万,算法只占用「常数级」的内存空间。
- 只申请了 几个临时变量,没有申请新的数组 / 列表 / 容器,内存占用「一丁点」,完全可以忽略不计。
- 所有空间复杂度为 O(1) 的排序算法,都叫做 原地排序算法 —— 排序过程中,只在原始数组上操作,没有开辟新的数组存储数据,这是排序算法的顶级优点!
- 冒泡排序、选择排序、插入排序三者的空间复杂度全部都是O(1)
- O(logn):算法执行过程中,额外申请的空间,会随着数据量n的增大而增大,但增长速度极慢,增长规律和 logn 一致:n 翻倍,空间只增加一点点。
- 和时间复杂度的O(logn)逻辑一致:n=1000,空间只需要约 10 个单位;n=100 万,空间只需要约 20 个单位;n=10 亿,空间只需要约 30 个单位,空间占用几乎可以忽略。
- 所有排序算法中,只有 快速排序(Quick Sort) 的空间复杂度是O(logn),这个空间开销不是来自申请变量 / 数组,而是来自「递归调用」产生的调用栈空间。
- O(n):算法执行过程中,额外申请的空间和数据量 n「成正比」:n 越大,申请的空间就越多,n 翻倍,空间也翻倍。
- 算法执行时,必须新开辟一个和原数组长度差不多的新数组 / 容器,用来存储中间数据,这个新数组的空间开销就是核心,也是导致空间复杂度为O(n)的直接原因。
- 归并排序(Merge Sort)空间复杂度固定为O(n)
- 归并排序不是原地排序算法,必须额外申请O(n)的空间,这是它唯一的缺点。
- O(n2):算法执行过程中,额外申请的空间和数据量 n 成「平方关系」,n 增大,空间会爆炸式增长。
算法的两个核心评价指标:时间复杂度 + 空间复杂度
二、冒泡排序 (Bubble Sort) - 相邻比较,慢慢 "浮" 上去
2.1 排序原理
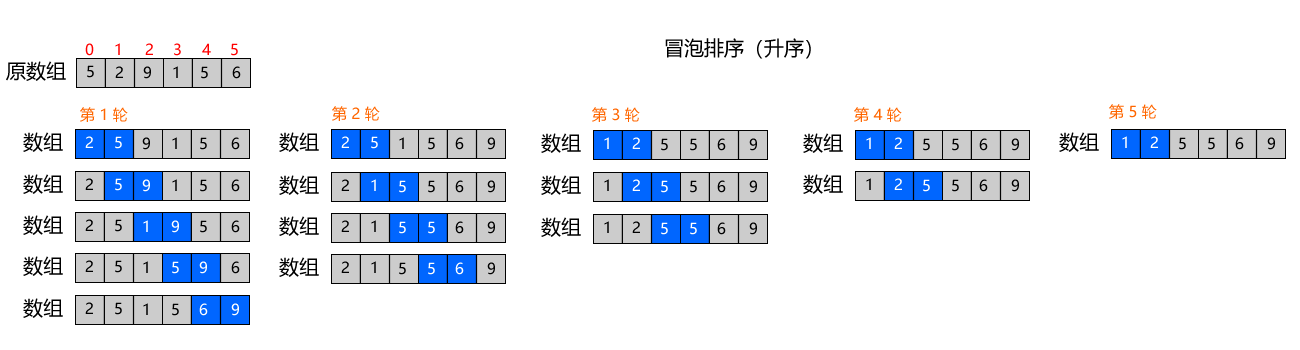
相邻的两个元素两两比较,如果顺序错了(前大后小)就交换位置;每一轮排序,都会把当前「最大的元素」像水里的气泡一样,慢慢 "浮" 到数组的最后面。
从小到大升序排序为目标,排序数组 [5,2,9,1,5,6],共 6 个元素,最多只需要排 5 轮(最后 1 个元素自然有序)
执行步骤:
- 第 1 轮:从左到右,依次比较相邻元素 → 5 和 2 交换、9 和 1 交换、9 和 5 交换、9 和 6 交换 → 最大的数9跑到最后一位,归位不动了;
- 第 2 轮:只比较前面的 5 个元素,重复相邻比较交换 → 次大的数6跑到倒数第二位,归位不动了;
- 每完成一轮,末尾就多一个有序的数,后续只需要排前面的无序部分,直到所有元素有序。
2.2 代码实现
#include <stdio.h>
// 交换函数
void swap(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 打印函数
void printArray(int arr[], int len) {
for (int i = 0; i < len; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
// 冒泡排序 升序
void bubbleSort(int arr[], int len) {
// 外层循环:控制排序轮数,n个元素最多n-1轮
for (int i = 0; i < len - 1; i++) {
// 内层循环:控制每轮比较次数,每轮减少i次(末尾i个元素已排序)
for (int j = 0; j < len - 1 - i; j++) {
// 相邻元素比较,前大后小则交换(升序)
if (arr[j] > arr[j+1]) {
swap(arr, j, j+1);
}
}
}
}
int main() {
int arr[] = {5, 2, 9, 1, 5, 6};
int len = sizeof(arr) / sizeof(arr[0]);
printf("冒泡排序前:");
printArray(arr, len);
bubbleSort(arr, len);
printf("冒泡排序后:");
printArray(arr, len);
return 0;
}
三、选择排序 (Selection Sort) - 先找最值,再一次性交换
3.1 排序原理
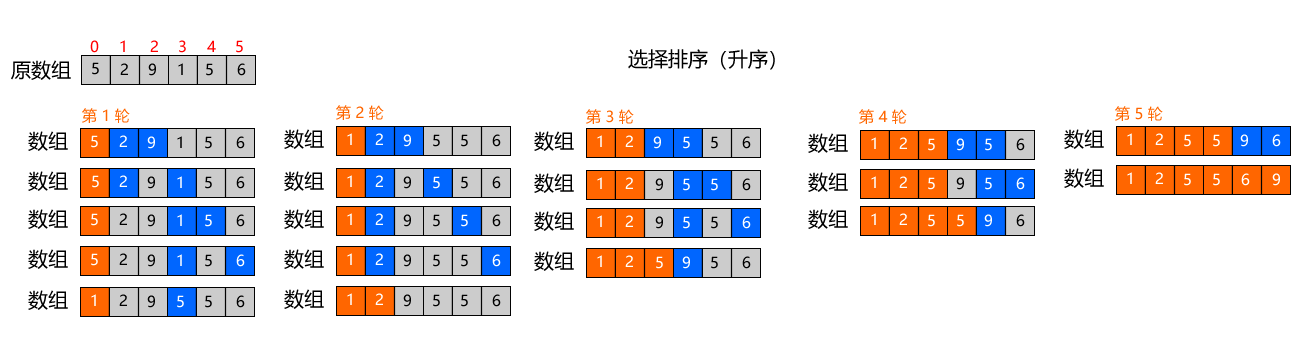
把数组分成「左边有序区」和「右边无序区」,每一轮都在「无序区」中找到「最小的元素」,然后把它和「无序区的第一个元素」交换位置。
从小到大升序排序为目标,排序数组 [5,2,9,1,5,6],共 6 个元素,最多排 5 轮
执行步骤:
- 第 1 轮:无序区是整个数组,找到最小值1,和数组第一个元素5交换 → 有序区:[1],无序区:[2,9,5,5,6];
- 第 2 轮:无序区是[2,9,5,5,6],找到最小值2,和无序区第一个元素2交换(不用动)→ 有序区:[1,2];
- 第 3 轮:无序区是[9,5,5,6],找到最小值5,和无序区第一个元素9交换 → 有序区:[1,2,5];
- 每完成一轮,有序区向右扩大 1 位,无序区缩小 1 位,直到覆盖整个数组。
3.2 和冒泡区别
- 冒泡排序是「边比较边交换」,每发现一对逆序就交换一次,交换次数多;
- 选择排序是「先找最值再交换」,不管找最值的过程比较多少次,每一轮最多只交换 1 次,交换次数极少(最多 n-1 次)。
- 选择排序没有有效优化方案,哪怕数组本身有序,也必须遍历完无序区找到最小值,所以它的最优 / 最坏效率都是 O(n2)。
3.3 代码实现
#include <stdio.h>
void swap(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
void printArray(int arr[], int len) {
for (int i = 0; i < len; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
// 选择排序 升序
void selectionSort(int arr[], int len) {
// 外层循环:控制有序区间的末尾,n个元素最多n-1轮
for (int i = 0; i < len - 1; i++) {
int minIndex = i; // 假设无序区间第一个元素是最小值,记录其下标
// 内层循环:遍历无序区间,找到最小值的下标
for (int j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j; // 更新最小值下标
}
}
// 找到最小值后,和无序区间第一个元素交换
swap(arr, i, minIndex);
}
}
int main() {
int arr[] = {5, 2, 9, 1, 5, 6};
int len = sizeof(arr) / sizeof(arr[0]);
printf("选择排序前:");
printArray(arr, len);
selectionSort(arr, len);
printf("选择排序后:");
printArray(arr, len);
return 0;
}
四、插入排序 (Insertion Sort) - 像理扑克牌一样排序(最实用)
4.1 排序原理
把数组分成「左边有序区」和「右边无序区」,默认第一个元素是有序区;依次取出无序区的元素,在有序区里「找到合适的位置插入」,插完后有序区依然保持有序。
这个逻辑和我们打扑克牌时整理手牌一模一样:摸一张新牌,从后往前和手里的牌比,大的牌往后挪,找到空位就把新牌插进去,手里的牌永远是有序的。
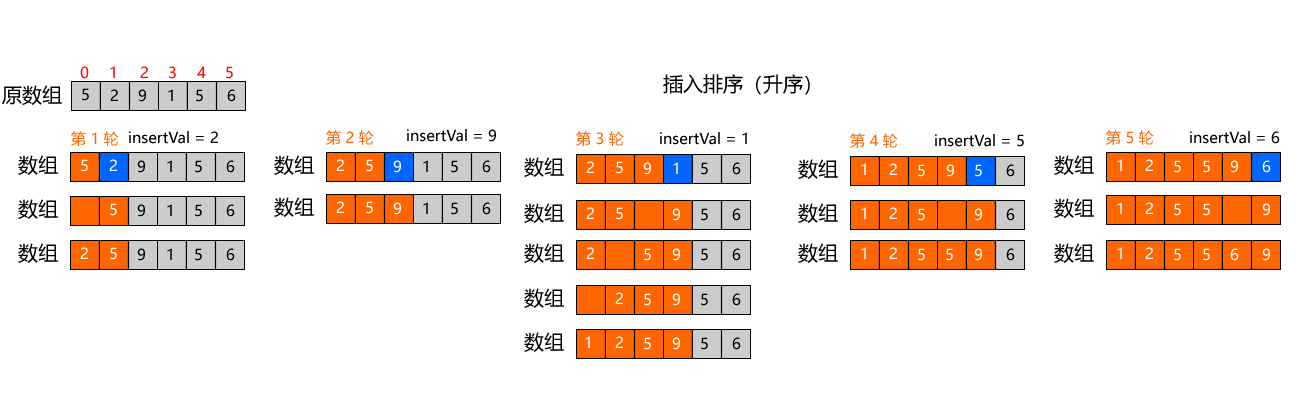
从小到大升序排序为目标,排序数组 [5,2,9,1,5,6],共 6 个元素,最多排 5 轮
执行步骤:
- 初始状态:有序区[5],无序区[2,9,1,5,6];
- 取无序区第一个元素2,和有序区的5比,2 更小 → 插入到 5 前面,有序区变成[2,5];
- 取无序区第一个元素9,和有序区最后一个元素5比,9 更大 → 直接插到末尾,有序区变成[2,5,9];
- 取无序区第一个元素1,依次和 9、5、2 比,都更小 → 插到最前面,有序区变成[1,2,5,9];
- 依次类推,直到所有元素都插入到有序区,排序完成。
4.2 核心优势
- 插入排序的核心动作是「元素移动」,而不是「元素交换」,移动的效率比交换高很多(交换需要 3 步赋值,移动只需要 1 步)。
- 而且,数组越接近有序,插入排序越快!如果数组本身有序,效率也是O(n),这也是为什么插入排序是这三个里面实际运行效率最高的排序。
4.3 代码实现
#include <stdio.h>
void printArray(int arr[], int len) {
for (int i = 0; i < len; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
// 插入排序 升序
void insertionSort(int arr[], int len) {
// 外层循环:遍历无序区间,从下标1开始(下标0是初始有序区间)
for (int i = 1; i < len; i++) {
int insertVal = arr[i]; // 取出当前要插入的元素
int preIndex = i - 1; // 有序区间的最后一个元素下标
// 内层循环:向前找插入位置,有序元素 > 待插入元素 则后移
// preIndex >= 0 防止数组下标越界
while (preIndex >= 0 && arr[preIndex] > insertVal) {
arr[preIndex + 1] = arr[preIndex]; // 元素后移,腾出插入空间
preIndex--;
}
arr[preIndex + 1] = insertVal; // 找到位置,插入元素
}
}
int main() {
int arr[] = {5, 2, 9, 1, 5, 6};
int len = sizeof(arr) / sizeof(arr[0]);
printf("插入排序前:");
printArray(arr, len);
insertionSort(arr, len);
printf("插入排序后:");
printArray(arr, len);
return 0;
}
五、三大排序核心对比
| 对比维度 | 插入排序 | 选择排序 | 冒泡排序 |
|---|---|---|---|
| 时间复杂度 | 全部O(n2) | 最好O(n)最坏O(n2) | 全部O(n2) |
| 空间复杂度 | O(1) | O(1) | O(1) |
| 稳定性 | 稳定 | 不稳定 | 稳定 |
| 核心特点 | 像理牌、移动为主、效率最高 | 找最值再交换、交换次数少 | 相邻交换、易理解、交换次数多 |
六、适用场景
这三个排序的效率都是O(n2),看起来不高,但绝对不是没用的算法,它们的适用场景非常明确:
- 只适合「小规模数据排序」(比如数组元素个数 < 1000),数据量小的时候,O(n2)和O(nlogn)的高级排序(快排、归并)效率差距很小,而且这三个排序代码更简单、更容易实现。
- 插入排序的特殊场景:如果你的数组「本身就很接近有序」(比如只有少数元素位置不对),插入排序的效率会无限接近 O(n),比快排还快!这也是为什么很多高级排序的底层,都会用到插入排序做优化。
- 选择排序的特殊场景:如果你的数据「交换成本很高」(比如数据是超大的对象,交换一次要耗很多内存),选择排序是最优的,因为它的交换次数最少。
七、总结
- 三大基础排序的核心逻辑,本质都是「分治思想」:把大的无序数组,拆成「有序区」和「无序区」,一步步把无序区缩小,直到整个数组有序;
- 三者的效率差异:插入排序 > 选择排序 > 冒泡排序,实际开发中优先用插入排序;
- 稳定性:插入、冒泡稳定,选择不稳定;
- 适用场景:小规模数据 + 近乎有序的数组,这三个排序是最优选择。
掌握这三个排序,你就打好了排序算法的基础,后续学习快速排序、归并排序等高级排序,会非常轻松!
返回顶部